Spark源码解析 - Spark SQL处理过程
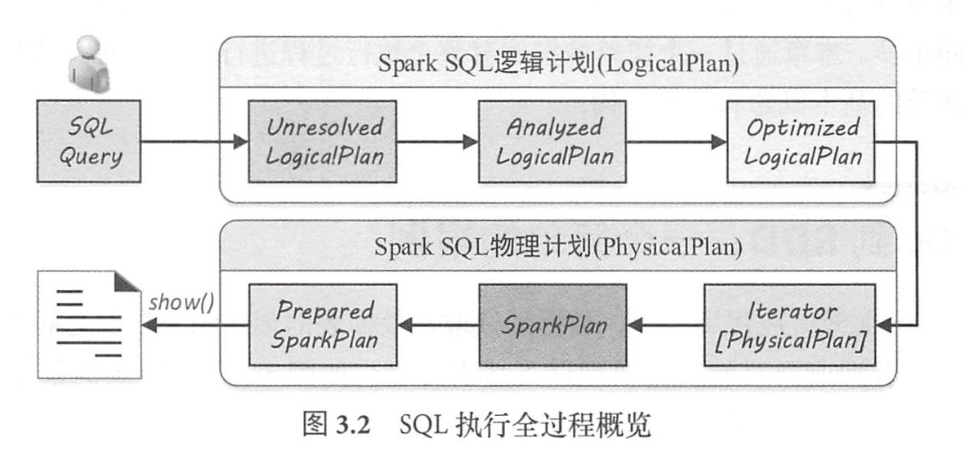
以Spark 3.2.0版本为基准,分析Spark SQL执行过程
Parsing阶段
Parsing阶段基于ANTLR4实现,用于将SQL解析为Unresolved Logical Plan。具体流程为,在执行SQL查询时,通过SparkSession的sessionState属性,调用sessionState.sqlParser.parsePlan方法进行解析。sqlParser内部实际借助AstBuilder,并采用访问者模式(Visitor Pattern),遍历ANTLR4生成的各类语法树Context节点,将其转换为对应的LogicalPlan节点,最终构建出Unresolved Logical Plan语法树。
Parsing关键调用链
sessionState.sqlParser.parsePlan(sqlText)经过Parser处理生成Unresolved Logical Plan
1 | org.apache.spark.sql.SparkSession#sql:616 |
sequenceDiagram
participant SparkSession
participant AbstractSqlParser
participant AstBuilder
SparkSession->>AbstractSqlParser: parsePlan(78)
AbstractSqlParser->>AstBuilder: visitSingleStatement(78)
Note right of AstBuilder: 至此生成Unresolved Logical Plan
Parsing关键组件
AbstractSqlParser
CatalystSqlParser和SparkSqlParser
其中CatalystSqlParser仅用于Catalyst内部,而SparkSqlParser用于外部调用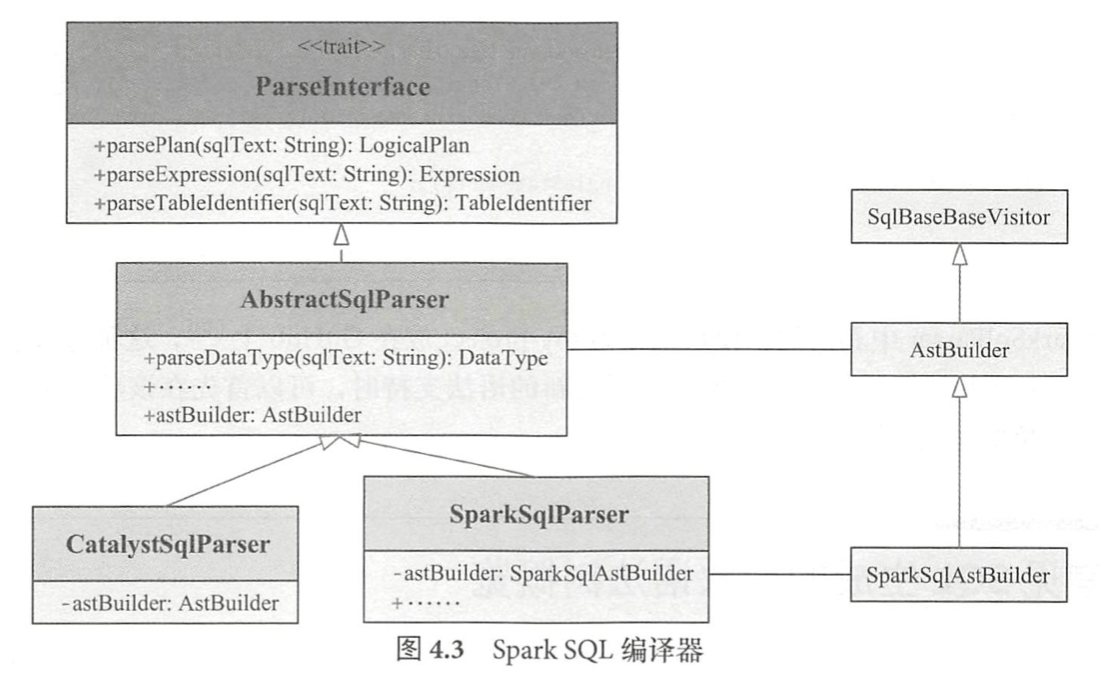
AstBuilder
AstBuilder继承了ANTLR4生成的默认SqlBaseBaseVisitor,将语法树的各种Context节点转换成对应的LogicalPlan节点,从而成为树UnresolvedLogicalPlan。SparkSqlAstBuilder继承AstBuilder,并在其基础上定义了一些DDL语句的访问操作,主要在SparkSqlParser中调用。
ANTLR4
基于SqlBase.g4文件生成SQL词法语法相关类文件,其中SqlBaseLexer是词法解析器,SqlBaseParser是语法解析器,并生成了监听器(SqlBaseListener/SqlBaseBaseListener)和访问者(SqlBaseVisitor/SqlBaseBaseVisitor)两种访问语法树的方式,Spark SQL主要使用的是访问者模式,就是以上面说的模式访问语法树
- SqlBaseLexer:词法分析器。负责把SQL源代码拆分成一个个“词法单元”(Token),比如关键字、标识符、符号等。它只关心字符流如何分割成有意义的单元。
- SqlBaseParser:语法分析器。负责根据SQL的语法规则,把词法单元序列组织成语法结构(如表达式、语句、查询块等),并生成语法树(Parse Tree),为后续的SQL语义分析和执行做准备
访问者模式
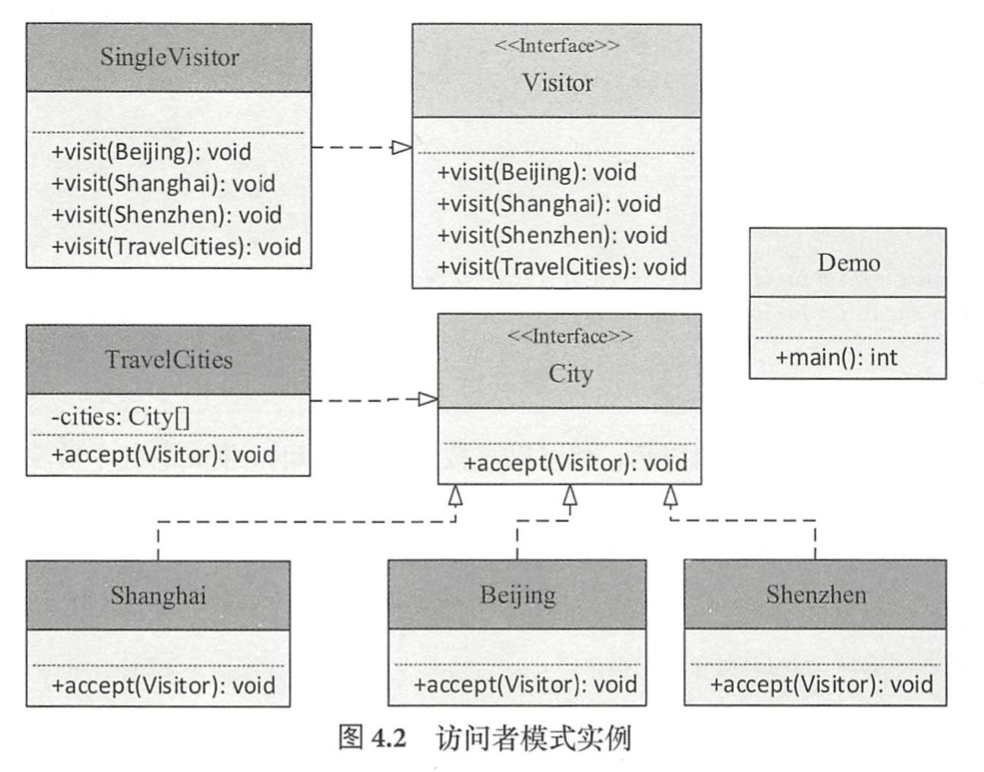
类似如下,定义了City接口以及具体的三个城市实现,和一个城市旅行计划
1 | public interface City { |
定义了Vistor接口,以及具体的访问者实现类
1 | public interface Visitor { |
则通过访问计划可以访问所有的城市,针对不同的城市作出不同的行为
1 | public class Demo { |
使用访问者模式把结构和行为分离,如果需要多增加行为,则添加新的Visitor或重载已有的Visitor并修改特定的访问行为。
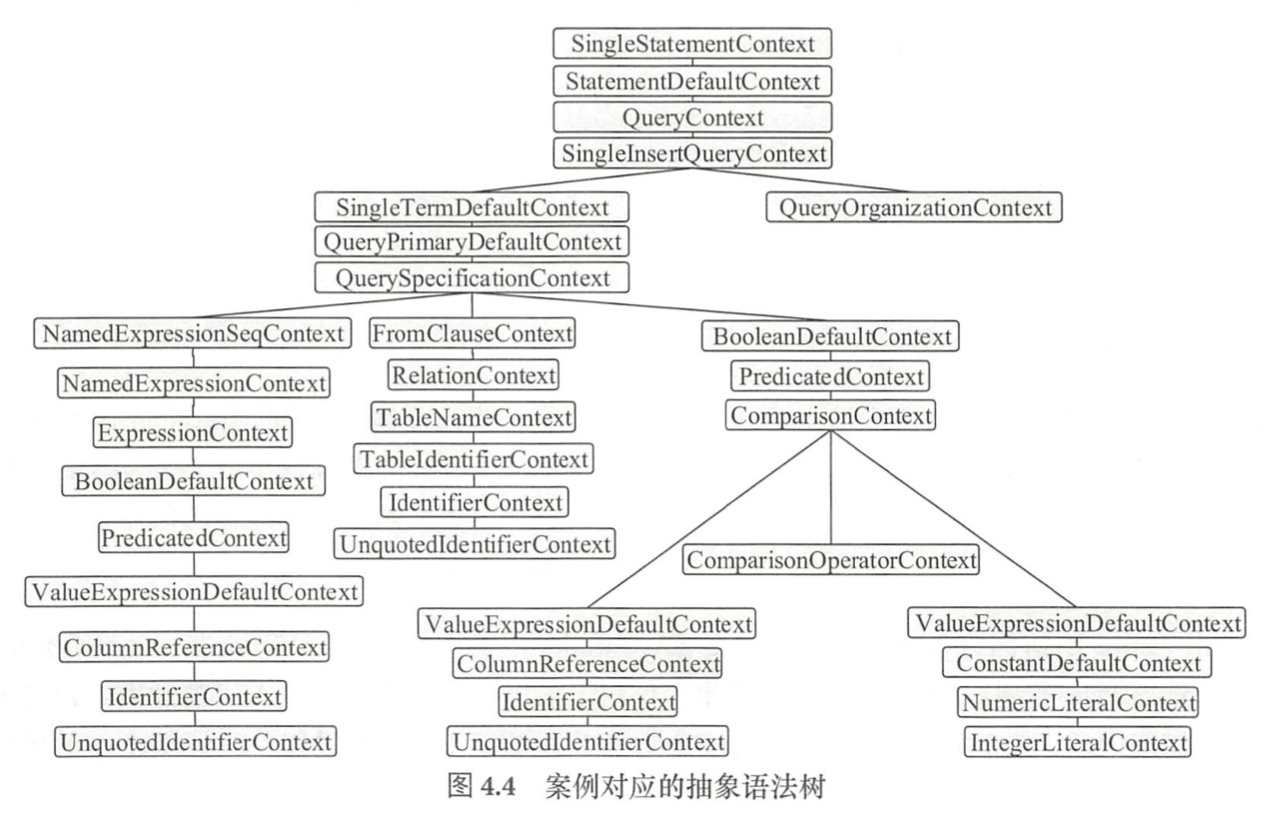
Unresolved Logical Plan示例
常规SQL产生的Unresolved Logical Plan如下
1 | select name f俨om student where age > 18 order by id desc |
Analysis阶段
TODO: 补充 Analysis 阶段内容
Optimization
Optimization阶段在action算子处被触发
以DataFrame#show操作为例,追踪下Optimize优化处理的调用链
1 | org.apache.spark.sql.Dataset#show:774 |
sequenceDiagram
participant Dataset
participant SQLExecution
participant QueryExecution
Dataset->>Dataset: show(774)
Dataset->>Dataset: showString(326)
Dataset->>Dataset: getRows(287)
Note right of Dataset: 此处实际调用了take这个action算子
Dataset->>Dataset: head(2728)
Note right of Dataset: 此处实际调用了head这个action算子
Dataset->>Dataset: withAction(3704)
Dataset->>SQLExecution: withNewExecutionId(98)
Note right of SQLExecution: 注释说在下一行queryExecution.executedPlan处触发了执行计划初始化,实则在这一行queryExecution.explainString就已经触发了初始化
SQLExecution->>QueryExecution: explainString(228)
QueryExecution->>QueryExecution: explainString(259)
QueryExecution->>QueryExecution: simpleString(214)
QueryExecution->>QueryExecution: executedPlan(166)
QueryExecution->>QueryExecution: optimizedPlan(138)
Note right of QueryExecution: optimizer.executeAndTrack即真正发起optimize的地方
Physical Planning
1 | // ... ... |
sequenceDiagram
participant QueryExecution
QueryExecution->>QueryExecution: simpleString(214)
QueryExecution->>QueryExecution: executedPlan(170)
Note right of QueryExecution: 首次访问触发sparkPlan初始化
QueryExecution->>QueryExecution: sparkPlan(157)
QueryExecution->>QueryExecution: createSparkPlan(468)
Note right of QueryExecution: planner.plan真正生成物理执行计划
Preparation
Prepare 生成executedPlan调用链
1 | // ... ... |
sequenceDiagram
participant QueryExecution
QueryExecution->>QueryExecution: simpleString(214)
QueryExecution->>QueryExecution: executedPlan(170)Spark源码解析 - Spark SQL处理过程
https://jszero.github.io/2025/08/09/Spark源码解析-Spark-SQL处理过程/